
Article· Updated June 2026
I let Claude run a peptide wiki I knew nothing about

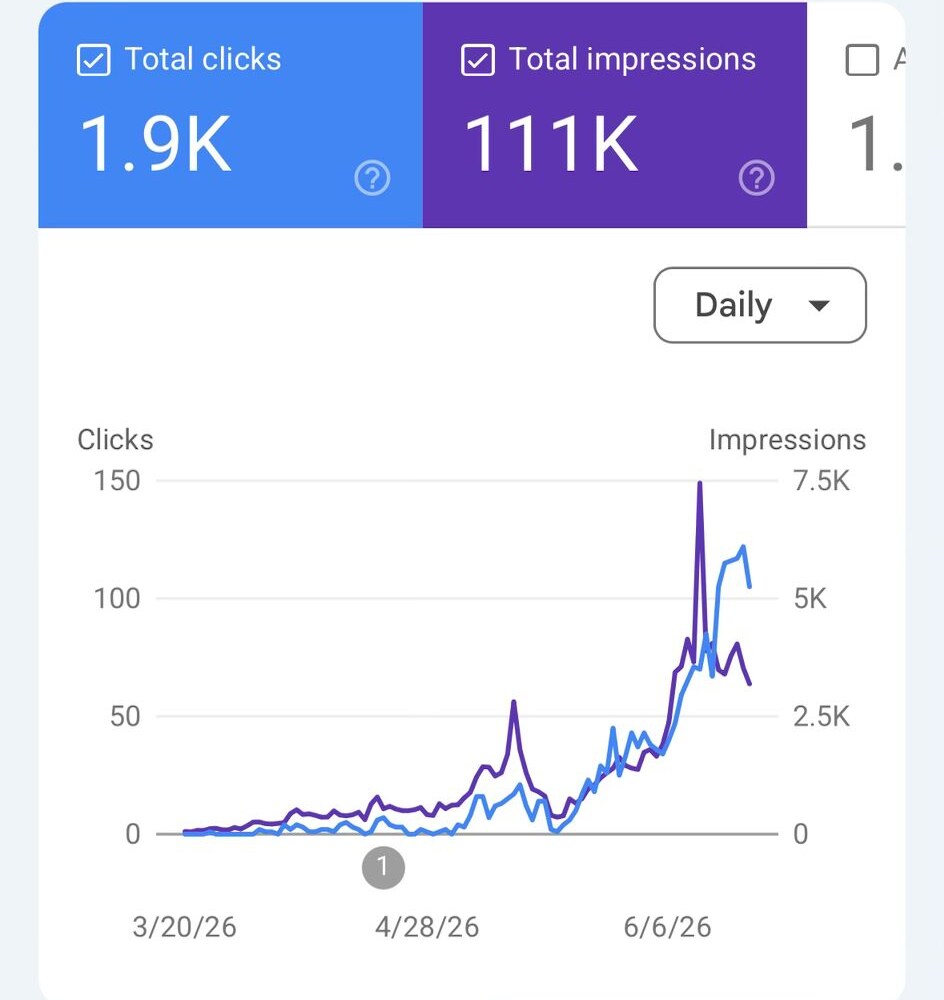
I can't tell you what retatrutide does. I haven't written an article for glp3.wiki in two months. It just crossed 111,000 impressions on Google.
A stranger on X asked me what I didn't expect to work that actually did. I told him: I picked a niche I knew nothing about, to learn programmatic SEO, and let Claude run it. He asked the obvious follow-up: what does “letting Claude run it” actually look like?
Here's the whole setup, the tools, and the loop prompt at the end, so you can point it at your own niche.
Why peptides
I wasn't trying to build a peptide wiki. I saw Andrew Huberman call retatrutide a “trillion-dollar drug” about to change everything, watched the replies go feral, and thought: clearly there's demand here, and I understand none of it. Perfect.
Perfect, because the topic didn't matter. The cleanest way to test a method is to take yourself out of it. If I'd picked something I knew, like Claude Code, I'd have leaned on what I already knew and never found out whether the system worked. Knowing nothing forced the agent to do the research and the writing itself. None of what follows needed me to know what a GLP receptor is.
The loop has since written the site's own explainer on what Huberman actually said. The thing that seeded the niche became one of its pages, and I had nothing to do with it.
What “letting Claude run it” looks like
One loop, fired daily by a scheduled job, doing six things.

- It reads its own scoreboard. Search Console and GA4, pulled from BigQuery, to see which pages gained or lost ground since yesterday.
- It listens to real people. Mines fresh Reddit threads on the topic for questions nobody has answered well yet. Those are the gaps.
- It kills its losers. Pages that aren't earning impressions get rewritten, merged, or removed. Pruning is half the ranking gain, and almost no one does it.
- It writes grounded, not slop. New content is researched against real sources before a word ships. Each page has to survive a skeptical reader, not just fill space.
- It ships behind a gate. The production build has to pass or nothing goes live, and a page that's winning is protected from risky edits.
- It repeats. Yesterday's output comes back as today's scoreboard, graded by Google.
What's missing from that list is me, picking topics. The agent picks them, from the data and from what real people are asking. I glance at the digest once a day and occasionally say “go deeper on X.”
What's actually running
People ask about the three marketing skills, but those are tools, not the engine. The engine is an orchestrator skill, glp3-daily, that runs the whole loop and holds the judgment: what to write, what to leave alone, what to roll back. Everything else is something it calls.

Walking the diagram:
- Mine. A gather step pulls only what changed since yesterday: new Reddit threads across 10 GLP-1 subreddits, new YouTube videos, rank-tracker movers from DataForSEO, ClinicalTrials.gov, Lilly and Novo press, and the Search Console queries where the site shows up but doesn't rank. These are the capabilities I've published as marketing-keyword-data, marketing-serp, and marketing-reddit. Install those and you have the mining half.
- Decide. The orchestrator scores each opportunity by Search Console position × GA4 pageviews, favouring page-2 pages that are one edit from page 1, then applies the hard rules (below) and picks at most a few changes.
- Ground. Every factual claim is verified before it ships. This is Exa's job (next section).
- Write. A second skill,
content-ingest, turns the chosen source and keyword into MDX, additive only, never rewriting prose that already works. - Ship and verify. The build has to pass, it pushes to main, and the next run reads GA4 to see whether the edit actually helped.
The hard rules are what make it safe to leave alone. Additive edits only on main. At most three changes a run, and at most one new article. A seven-day cooldown per page (fourteen for the breadwinner). And a self-rollback: if a page that had real traffic drops more than 30% after an edit, the next run reverts the commit.
What Exa is, and how the loop uses it
Exa is a search API built for machines rather than people: you hand it a query or a claim and it returns the most relevant pages with their full text, so an agent can read and cite the actual source instead of trusting its own memory. For a medical site that is the whole ballgame — nothing ships from the model's recollection.
The loop calls it twice. Once to pull the source it's writing from, and again to verify every load-bearing number — a weight-loss percentage, a trial result, an FDA date — against a primary source before publishing. Anything it can't verify gets cut or flagged, never guessed. For paywalled journals that block a plain fetch (NEJM, The Lancet), it falls back to Firecrawl, which renders the page like a real browser.
# pull the source you're writing from
exa scrape "<url>" --max-chars 10000
# verify a specific claim against primary sources before it ships
exa search "retatrutide TRIUMPH weight loss percentage" --text -n 5Get your data into BigQuery
This is the step that makes autonomy possible, and almost no one takes it. Both Search Console and GA4 pipe into BigQuery in a few clicks: Search Console → Settings → Bulk data export; GA4 → Admin → BigQuery links. Then Claude queries your real traffic in whatever shape the question needs: URL by query by week, impressions joined to on-page behaviour, anything.

There's a Search Console MCP too, and it's a great on-ramp: OAuth, a fixed set of tools, working in minutes. But it serves sampled data through a fixed set of questions. BigQuery gives the agent every row, unsampled, and lets it write arbitrary SQL across Search Console and GA4 at once. Start with the MCP. Move to BigQuery when you want the agent to slice the data in ways a fixed tool can't.
What transfers to any niche
A few things carry over to any topic.
- Find the winner, then double down. The traffic didn't spread evenly across 57 pages. One page, the dosage guide, pulls 38% of the site's impressions and the large majority of its clicks. So the loop concentrated there: a dosing calculator, titration schedules, a dose-by-dose breakdown, and internal links pointing the rest of the site at it. The job was spotting the breakout, not adding more pages.
- A winner becomes production. Once a page carries real traffic, the loop stops experimenting on it. The dosage guide sits under a 14-day change freeze, double the 7 days an ordinary page gets; a daily canary watches its rank for drops; and a hard rule blocks edits even when high-impression query gaps point straight at it. New experiments move to lower-stakes pages instead. It handles its best page the way you'd handle prod.
- The agent needs a scoreboard it can read alone. That's the whole reason for BigQuery. Without one, it can't run unsupervised.
- The traffic is the verdict, not the build. After a change ships, the next run compares that page's GA4 pageviews for the week after against the week before. If a page that had real traffic drops more than 30%, it
git reverts the commit. (GA4 is the primary signal because most pages get more traffic from ChatGPT citing them than from Google; Search Console is a cross-check for the few pages that rank. The build is just a safety gate, not how it knows the writing landed.) - Prune ruthlessly. Cutting dead pages helped the rankings as much as writing new ones did.
I'm running the same playbook on two more sites
glp3.wiki is the proven one. The same setup now points at untrappable.com and drafty.im. The checklist is the same: wire the data into BigQuery, point the three skills at the new niche, set the daily loop, and wait. Neither has results yet, so treat this as one proof and two open bets.
The part that keeps it from flying blind
An autonomous loop nobody looks at will quietly drift. Changes ship while you sleep, and you find out something broke when the traffic does. So I keep a daily check on it.
Every run, it posts its digest to a Drafty canvas: what it changed, what's ranking, what it killed. I open it on my phone, point at a line, and leave a comment. Next run, the agent reads the comment and acts on it. That's the entire human-in-the-loop: a daily glance and the occasional nudge.
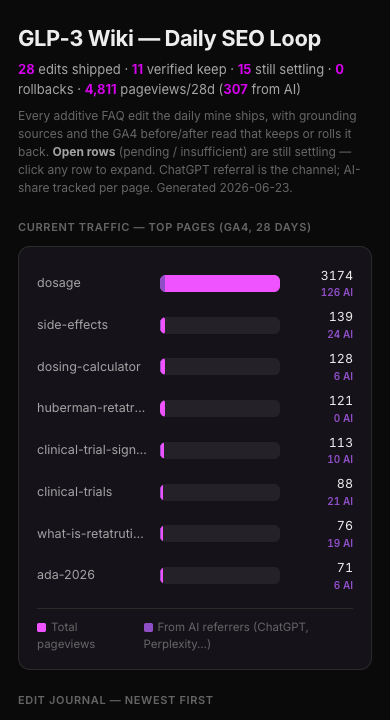
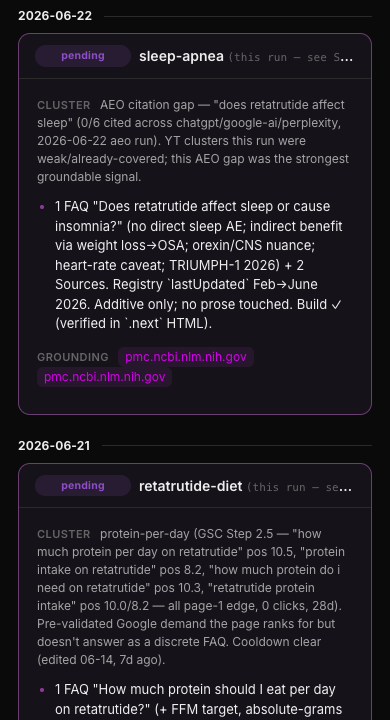
If you build one of these, build the daily check too. The autonomy is only safe because I can still see what it's doing.
The whole thing, to copy
This is the shape of the orchestrator, close to the real glp3-daily skill. Wire it to the mining skills, Exa, and a BigQuery-connected project, schedule it daily, and you have what runs glp3.wiki.
# daily SEO loop — runs unattended, once a day
0. Verify yesterday. Read the journal. For each past edit now due for
review, compare the page's GA4 pageviews (7 days before vs after). If a
page that had real traffic dropped >30%, git revert that commit.
0.5 Canary. Check the breadwinner page's Search Console rank
week-over-week. A drop of 3+ positions: stop and alert a human.
1. Mine. Pull only what changed since yesterday: new Reddit and YouTube
questions, rank-tracker movers, new trials and press, and the Search
Console queries where the site shows up but doesn't rank.
2. Cluster + dedupe. Group the questions. Drop anything already answered
(check the covered-questions ledger).
3. Score + pick. Rank opportunities by Search Console position x GA4
pageviews, favouring page-2 pages one edit from page 1. Obey the rules:
additive only, ~3 edits max, never touch a page inside its cooldown
(14 days for the breadwinner), never rewrite prose that works.
4. Ground + write. For the top pick, verify every claim against a primary
source with Exa (Firecrawl for paywalled journals). Patch the article
or draft a new one. Cut anything you can't verify.
5. Gate + ship. Run the production build. If it passes, push to main.
If it fails, don't ship.
6. Journal. Record what changed and when to verify it, so tomorrow's run
can check whether it worked, and a digest goes to the Drafty canvas.I picked a topic I knew nothing about, wrote three small skills, connected the data, and got out of the way. The impressions are real, and none of them needed me. Yours won't need you either.
Frequently asked
What is programmatic SEO (pSEO)?
Building many pages that each target a specific search, rather than writing a few big articles by hand. You publish broadly, but the traffic rarely spreads evenly. On glp3.wiki the dosage guide alone is about 38% of impressions, so the real work is spotting the breakout page and concentrating on it.
Can Claude really write SEO content unsupervised?
Within guardrails, yes. The guardrails are what matter: source-grounded research, a check on each change's Search Console numbers that keeps or rolls it back, and a daily digest a human actually reads. Without them you get slop. With them, the output holds up.
Won't Google penalise AI content?
Google penalises unhelpful content, AI or not. The loop's defence is built in: pages that don't earn impressions get removed instead of defended, so only what performs stays up.
Search Console MCP or BigQuery?
MCP to start, since it runs in minutes. BigQuery once you want unsampled data and arbitrary queries across Search Console and GA4. For an unattended loop, BigQuery is worth the setup, because the agent needs to slice the data in shapes a fixed tool can't.
How much does it cost to run?
It runs on a single Claude subscription plus BigQuery's free tier at this volume. The work is scoped and daily, not open-ended exploration, which is what keeps it cheap. The same pattern runs my morning analytics digests across subs.rip, journeys.im, and bq-analytics.
Can I do this for my own site?
Yes. Install the mining skills, wire your data into BigQuery, give Exa an API key for grounding, adapt the orchestrator prompt above, and post the digest somewhere you'll actually look. Start with one niche you can verify, and let the scoreboard tell you what to keep.