
Article· Updated June 2026
My skills go stale in two months

glp3.wiki gets about 600 readers a week. Roughly half of them show up because ChatGPT cited it, not because Google ranked it. I haven't written or edited a word on it in weeks — Claude does that now, on a loop, and I check in maybe once a week.
It's not a toy setup. GA4 and Search Console both pipe into BigQuery, and Claude queries them with the bq CLI to see which pages get read and where the readers come from — that's how I know half the traffic is ChatGPT citing the page. A keyword API (DataForSEO, wrapped as a skill) tells it what people are actually searching. And a scraper (Firecrawl) pulls the primary source itself — the NEJM paper, the ClinicalTrials.gov entry — through the soft paywalls that stop a plain fetch, so the article cites the study, not a press release about it. The loop is: spot demand in the numbers, research the source, write or update the article, publish. For a reference wiki, that's most of the job, and it runs without me.
Here's the catch. It had been doing all of that on skills I'd written months earlier and not touched since. In AI time, a few months is old.
What stale skills look like
You couldn't see it in the traffic — the content loop doesn't care how the page looks. You could see it the moment you opened the site.
Abstract watercolour heroes, generated by an older Gemini model. A friendly blue. Inter. A blue-circle favicon. It looked like what it started as — a blog. The look was a fossil of an earlier version of me: the copy skill, the design skill, the image skill were all the best I had when I wrote them, and I'd quietly gotten better since, on other projects, without ever coming back to update this one.

New skills
So I gave it the current set. A copy voice (brand-copy), a design playbook (brand-design), and a newer image skill (GPT Image 2) to replace the watercolour generator — all sharpened on other work in the months since — dropped straight in. Then I wrote the brief and told it to rebrand.
The brief itself was opinionated, because the skills now carry opinions:
- Monochrome chrome, colour only from the imagery. No brand colour anywhere in the interface; light and dark as separate palettes, not inverts.
- Type with a point of view. Space Grotesk for display, Hanken Grotesk for body, and exactly one word set in Instrument Serif italic — explained.
- A library of six film-grain photo treatments, chosen per topic, instead of one decorative wash repeated 90 times.
- A trust strip of the primary sources it actually cites — NEJM, The Lancet, JAMA, the FDA, ClinicalTrials.gov.
- A three-dots mark for the triple agonist.
None of that was me typing instructions in the moment — the skills carried the opinions. I steered lightly (named the audience, made a few taste calls), but I was tuning a direction the skills already had, not supplying one.
What it shipped
The whole site moved from decorative to deliberate: real, film-grain photography in place of the washes, one of six hero treatments chosen per topic.

The home hero shows the swap most directly: the same headline, a different image skill behind it.


And every article page got the same shift.


The change I care about most doesn't show up in a hero shot: the new design wears its sources. When an article names a person — a researcher, a podcaster, a clinician — the name becomes an inline mention: a small avatar and a link, right in the sentence, so you can see who's being quoted and go check them.

The trust is structural, not decorative. The site leads with the primary sources it's grounded in — NEJM, The Lancet, JAMA, ClinicalTrials.gov, the FDA — and names the viral voices it fact-checks, each with their real avatar. For a medical page, pointing outward at a real authority is the trust signal, and it's exactly what an answer engine checks before it cites you.
Same model running the site. Same project. The only thing that changed was the quality of the skills it was working from.
Skills go stale fast — and that's the upgrade
The thing that stuck with me is how quickly the old skills had aged. A couple of months, and the playbook was visibly behind. AI moves fast enough now that revisiting and sharpening your skills is one of the highest-leverage things you can do — a better skill set re-skins a whole site without you touching a component.
There's a second-order effect I didn't appreciate until this. Before, my “skills” lived in my head. To apply a copy sense or a design eye I had to internalise it, get genuinely good at it, and then carry it by hand to the next project — relearning the friction each time, often not bothering. Now a skill is a file. The design playbook I'd sharpened on a different project this month dropped into the wiki unchanged. Every lesson I write down compounds across every project an agent can reach, instead of staying trapped in the one place I learned it.
The site is live at glp3.wiki. It's early, and I'm not reading too much into it yet — but the last three months are heading the right way, with clicks and impressions both climbing:
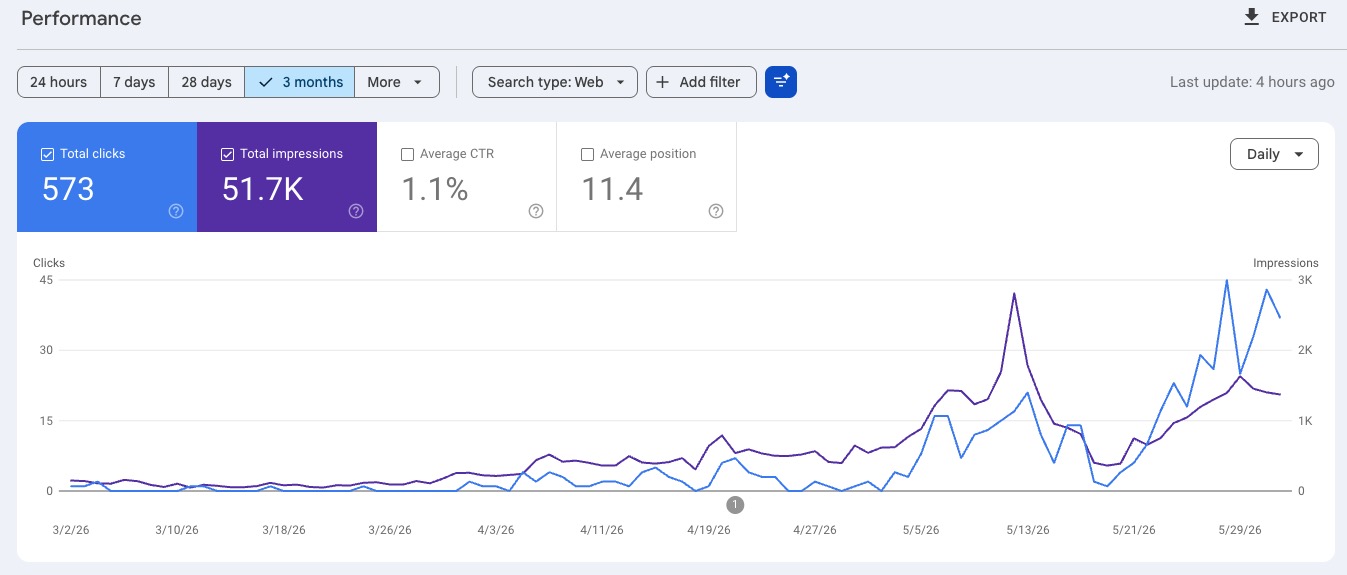
I'm betting the rest follows the same logic: double down on the audience the skills finally named, and on the channel that's already working — the ChatGPT citations — and the growth should compound too. I'll report back on whether it does.
Frequently asked
Should you rewrite your skills every time a new model ships?
Reread them, at least — that's where the leverage hides. Anthropic does this with Claude Code itself: Cat Wu, who runs product on it, told Lenny's Podcast that the team rereads the entire system prompt at every model launch and removes any reminder the new model no longer needs. Her example is the to-do list — it started as a crutch for models that would change five of twenty call sites and stop, and Opus 4 and later reach for it unprompted. Skills accumulate the same scar tissue: a lot of the instructions in an old skill exist to work around a model weakness that has quietly stopped existing. Deleting those is often the whole upgrade.
When is a loop reliable enough to run without you?
When it works every time, not most times. Cat Wu's bar in the same conversation: an automation that works 95% of the time isn't really an automation, because you still have to check it — "there's not much value in a 95%-there automation." That matches my experience with the glp3.wiki loop. The version I check weekly only became possible after the boring last mile was paid down — the data gates, the build gate, the rollback rule — and the skills are where that teaching accumulates. Feedback you give the agent evaporates with the session unless it lands in a file.
Where do skills end and CLAUDE.md and MCP begin?
They split by when the context loads, and that split is the whole reason a skill scales where CLAUDE.md doesn't. CLAUDE.md is always in context — every fact in it is a tax you pay on every turn — so it should hold facts the agent needs constantly, not procedures. Anthropic's own guidance is to reach for a skill "when a section of CLAUDE.md has grown into a procedure rather than a fact," because, in their words, "unlike CLAUDE.md content, a skill's body loads only when it's used, so long reference material costs almost nothing until you need it." That's how the glp3.wiki loop carries a copy voice, a design playbook, and an image skill without drowning every prompt in instructions it isn't using right now — Claude reads each skill's name and description, then pulls the full body only when the task calls for it. MCP is the third leg: where a skill is instructions, MCP is the live connection — the GA4 and Search Console data, the keyword API, the scraper. A skill can even bundle its own MCP servers and hooks, so "refresh the skill" ends up meaning the playbook and the tools it reaches for, in one file that travels to every project the agent touches.